

Criando um cluster Kubernetes com kubeadm, HAProxy e Keepalived usando uma infraestrutura on-premises em alta disponibilidade.
Com imensa gratidão, compartilho que este artigo serviu como alicerce para o workshop que ministrei em 25/11/2023 para os alunos da Formação DevOps Pro. Agradeço sinceramente pela oportunidade de disseminar conhecimento entre meus colegas de curso. Ao ingressar na turma em novembro de 2022, mal conseguia pronunciar os nomes dos componentes do Kubernetes. Contudo, graças às aulas, conquistei a habilidade de mergulhar em uma nova oportunidade profissional no Luizalabs, do grupo Magazine Luiza. Atualmente, atuo como um dos administradores, gerenciando múltiplos clusters Kubernetes.
É fascinante perceber como a jornada de aprendizado acelerado abriu portas para desafios empolgantes e estimulantes na minha carreira. Escrevo este trecho do artigo com a consciência de que, em menos de 48 horas, estarei enfrentando o exame da Certified Kubernetes Administrator (CKA) pela Linux Foundation. Este desafio, longe de ser uma barreira, representa mais uma etapa emocionante na minha trajetória de crescimento profissional.
Agradeço novamente pela oportunidade de compartilhar conhecimento e experiência, e estou animado para continuar aprendendo e contribuindo para o campo de DevOps.
Neste artigo, apresentarei um guia abrangente sobre a criação de um cluster Kubernetes altamente disponível, configurado para um ambiente praticamente pronto para produção, composto por 3 nós de controle (control planes) e 3 nós de trabalho (workers). Esses passos podem ser reproduzidos com facilidade em qualquer ambiente, seja em nuvem privada, pública ou até mesmo em ambientes on-premises.
Os etapas seguintes não apenas proporcionarão a construção de um ambiente robusto, mas também servirá como um laboratório ideal para aqueles que estão se preparando para o exame Certified Kubernetes Administrator (CKA). Esta certificação é reconhecida como uma das mais desafiadoras devido à complexidade inerente a um cluster Kubernetes.
Ao seguir este guia, você estará não apenas configurando um cluster Kubernetes, mas também estará imerso em práticas e conceitos essenciais que são fundamentais para um administrador de Kubernetes.
Pré-requisitos
Neste artigo, a abordagem adotada permite a utilização em ambientes de nuvem privada, pública ou on-premises. Contudo, para manter uma coerência na apresentação, optaremos por utilizar o provedor AWS, dada sua ampla popularidade entre os usuários de serviços de nuvem.
Para implementar o cluster Kubernetes proposto, serão provisionadas um total de 8 instâncias EC2, cada uma configurada com as seguintes especificações:
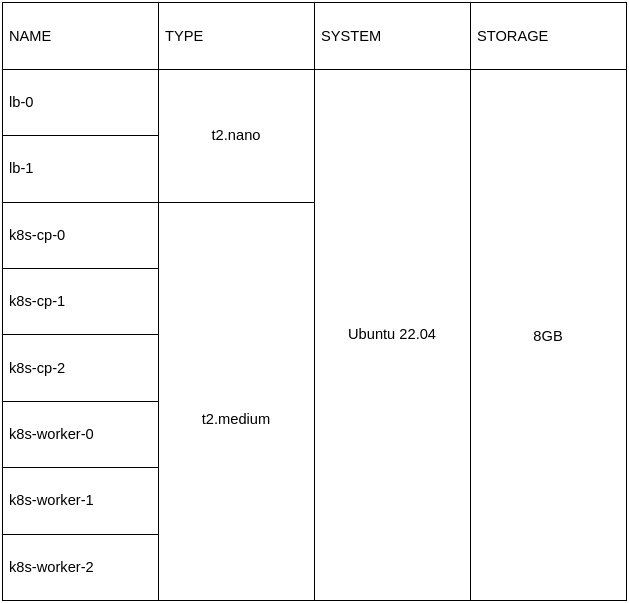
Ao criar as instâncias, é imprescindível associar um grupo de segurança. Certifique-se de adicionar uma regra que permita a comunicação na porta 6443 entre as instâncias.
Adicionalmente, será empregado um único Elastic IP para simplificar a configuração.
É crucial observar que, para facilitar as etapas descritas neste artigo, é essencial preencher corretamente o hostname de cada instância conforme indicado.
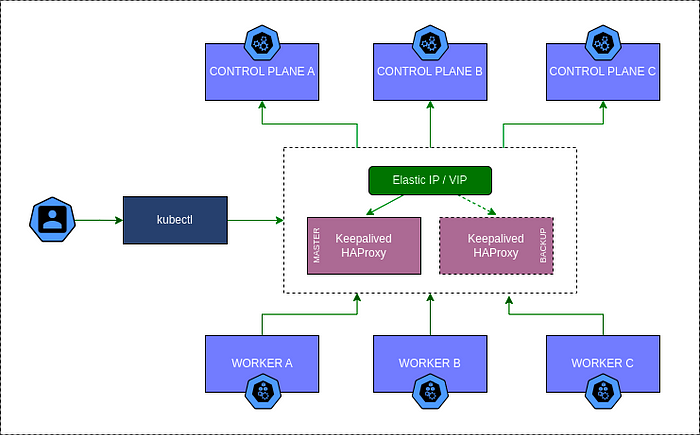
Arquitetura do cluster
A arquitetura do cluster Kubernetes abrange os nós de controle, nós de trabalho, nós de proxy e o Elastic IP.
Configurando um Elastic IP
No console da AWS, inicie criando uma Identity and Access Management (IAM) para conceder permissões ao serviço Elastic IP.
Certifique-se de fazer o download das credenciais e armazená-las em um local seguro, preferencialmente em seu computador.
Posteriormente, instale a AWS Command Line Interface (CLI) nas instâncias lb-0 e lb-1, permitindo assim a interação eficaz com o serviço Elastic IP.
apt update -y
apt install -y python-is-python3 python3.10-venv unzip jq
curl "https://s3.amazonaws.com/aws-cli/awscli-bundle.zip" -o "awscli-bundle.zip"
unzip awscli-bundle.zip
./awscli-bundle/install -i /usr/local/aws -b /usr/local/bin/awsA seguir, configure a AWS Command Line Interface (CLI) com os dados da credencial baixada anteriormente:
aws configure
AWS Access Key ID [None]: <ACCESS_KEY>
AWS Secret Access Key [None]: <SECRET_KEY>
Default region name [None]: <REGION>
Default output format [None]: jsonAgora, as instâncias estão devidamente configuradas para interagir com o serviço Elastic IP, que realizará a alternância do endereço IP sempre que uma das instâncias (lb-0 ou lb-1) estiver indisponível.
Instalando HAProxy e Keepalived
Nas instâncias já provisionadas lb-0 e lb-1, vamos iniciar as instalações e configurações necessárias.
Inicie com a atualização do sistema, instalação do HAProxy e do Keepalived:
apt update -y
apt install haproxy keepalived -y
systemctl enable haproxy keepalived --nowConfigure o HAProxy:
cat <<EOF | tee -a /etc/haproxy/haproxy.cfg
frontend k8s-ha
bind *:6443
option tcplog
mode tcp
default_backend k8s-cps
backend k8s-cps
mode tcp
balance roundrobin
option tcp-check
server k8s-cp-0 IP_CONTROL_PLANE_0:6443 check fall 3 rise 2
server k8s-cp-1 IP_CONTROL_PLANE_1:6443 check fall 3 rise 2
server k8s-cp-2 IP_CONTROL_PLANE_2:6443 check fall 3 rise 2
EOFAtive e reinicie o serviço HAProxy:
systemctl restart haproxyOs logs do HAProxy podem verificados:
tail -f /var/log/haproxy.logLembrando que, até este ponto, o procedimento deve ser replicado de maneira idêntica nas duas instâncias denominadas lb-0 e lb-1.
A seguir, será configurado o Keepalived na instância lb-0:
cat <<EOF | tee -a /etc/keepalived/keepalived.conf
vrrp_script chk_service {
script "/usr/lib/keepalived/ha-check"
interval 3
weight 50
}
vrrp_instance VI_1 {
interface eth0
priority <PRIORITY>
virtual_router_id 51
advert_int 1
unicast_src_ip <MASTER_IP>
unicast_peer {
<BACKUP_IP>
}
authentication {
auth_type PASS
auth_pass <PASS>
}
track_script {
chk_service
}
notify "/usr/lib/keepalived/ha-notify"
}
EOFConfigurando o Keepalived na instancia lb-1:
cat <<EOF | tee -a /etc/keepalived/keepalived.conf
vrrp_script chk_service {
script "/usr/lib/keepalived/ha-check"
interval 3
weight 50
}
vrrp_instance VI_1 {
interface eth0
priority <PRIORITY>
virtual_router_id 51
advert_int 1
unicast_src_ip <BACKUP_IP>
unicast_peer {
<MASTER_IP>
}
authentication {
auth_type PASS
auth_pass <PASS>
}
track_script {
chk_service
}
notify "/usr/lib/keepalived/ha-notify"
}
EOFConfigure os scripts check e notify do keepalived
Os scripts check e notify desempenham o papel crucial de interagir com a CLI da AWS, facilitando a alteração do Elastic IP conforme necessário.
Para incorporar esses scripts, faça o download a partir do repositório https://github.com/erivaldolopes/ha-aws e configure-os nos diretórios apropriados nos nós Keepalived. Certifique-se de adicioná-los ao seguinte caminho: /usr/lib/keepalived/.
Antes de executar os scripts, é imperativo revisá-los e atualizar as variáveis correspondentes aos hostname internos das instâncias dos respectivos nós Keepalived.
Para validar o funcionamento eficaz do Keepalived:
- Verifique se as instâncias receberam o novo Elastic IP.
- Na instância com o Elastic IP atribuído, execute “systemctl stop haproxy”.
- Se todas as etapas foram concluídas com sucesso, agora a instância deve ter adquirido um novo IP dinâmico, enquanto a outra instância deve ter recebido o Elastic IP.
- Esse processo pode ser repetido entre as instâncias, de forma alternada.
Esteja atento a qualquer mensagem de erro durante o procedimento e ajuste conforme necessário para garantir a eficácia do Keepalived.
Configurando as instancias (nós do K8s)
Ao configurarmos um cluster com 3 nós de control planes e 3 nós de workers, totalizando 6 instâncias, otimizaremos o processo considerando que todos os comandos serão executados com o usuário root.
Vale ressaltar que neste cenário específico, estamos utilizando o sistema operacional Ubuntu 22.04.
Iniciaremos desativando a área de troca (swap) no sistema, assegurando que essa desativação seja persistente mesmo após reinicializações:
swapoff -a
(crontab -l 2>/dev/null; echo "@reboot /sbin/swapoff -a") | crontab - || trueHabilitando o trafego bridged do iptables:
cat <<EOF | tee /etc/modules-load.d/k8s.conf
overlaybr_netfilter
EOFmodprobe overlay
modprobe br_netfiltercat cat <<EOF | tee /etc/sysctl.d/k8s.confnet.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --systemInstalação do CRI-O Runtime: O CRI-O é um runtime de container leve que é compatível com o Kubernetes.
Habilite repositórios cri-o para a versão 1.28:
OS="xUbuntu_22.04"
VERSION="1.28"cat <<EOF | tee /etc/apt/sources.list.d/devel:kubic:libcontainers:stable.list
deb https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/$OS/ /
EOF
cat <<EOF | tee /etc/apt/sources.list.d/devel:kubic:libcontainers:stable:cri-o:$VERSION.list
deb http://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable:/cri-o:/$VERSION/$OS/ /
EOFAdicione as chaves GPG para CRI-O:
curl -L https://download.opensuse.org/repositories/devel:kubic:libcontainers:stable:cri-o:$VERSION/$OS/Release.key | apt-key --keyring /etc/apt/trusted.gpg.d/libcontainers.gpg add -
curl -L https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/$OS/Release.key | apt-key --keyring /etc/apt/trusted.gpg.d/libcontainers.gpg add -Instalando e ativando o CRI-O:
apt update -y
apt install cri-o cri-o-runc cri-tools -y
systemctl daemon-reload
systemctl enable crio --nowInstale kubeadm, kubelet e kubectl em todos os nós:
apt update -yapt install -y apt-transport-https ca-certificates curlBaixe a chave GPG para o repositório Kubernetes APT:
curl -fsSLo /usr/share/keyrings/kubernetes-archive-keyring.gpg https://dl.k8s.io/apt/doc/apt-key.gpgAdicione o repositório Kubernetes APT:
echo "deb [signed-by=/usr/share/keyrings/kubernetes-archive-keyring.gpg] https://apt.kubernetes.io/ kubernetes-xenial main" | tee /etc/apt/sources.list.d/kubernetes.listFaça a instalação:
apt update -y
apt install -y kubelet kubeadm kubectl
apt-mark hold kubelet kubeadm kubectlAplicando boas práticas, a apt-mark hold ativa a retenção para evitar update automático.
Configure o kubelet indicando o IP local correspondente ao nó:
apt install -y jqlocal_ip="$(ip --json addr show eth0 | jq -r '.[0].addr_info[] | select(.family == "inet") | .local')"cat > /etc/default/kubelet << EOF
KUBELET_EXTRA_ARGS=--node-ip=$local_ip
EOFCriando a control plane master
Para iniciar a criação de um cluster Kubernetes, é essencial estabelecer o primeiro nó de controle.
Ressalto que estamos construindo um cluster com alta disponibilidade, utilizando o HAProxy para distribuir a carga entre os nós. Assim, vamos empregar um IP público externo, representado pela variável PROXY_IP, para a inicialização do nosso primeiro nó de controle.
Certifique-se de ter as seguintes variáveis em mente durante o processo:
PROXY_IP: Este é o Elastic IP configurado nas instâncias, juntamente com o HAProxy e o Keepalived, conforme detalhado no início do artigo.POD_CIDR: Refere-se à rede interna pela qual os pods irão se comunicar. Geralmente, é configurada como um /16, como no exemplo a seguir: 10.40.0.0/16.
kubeadm init --control-plane-endpoint=$PROXY_IP \
--apiserver-cert-extra-sans=$PROXY_IP \
--pod-network-cidr=$POD_CIDRO parâmetro --ignore-preflight-errors Swap poderia ser empregado, no entanto, sua utilização não é necessária, uma vez que desativamos a área de troca (swap) durante a configuração dos nós.
Um detalhe crucial a ser observado é o parâmetro --apiserver-advertise-address, que seria útil em cenários onde não estamos implementando um cluster com alta disponibilidade. Para definir um endereço IP de alta disponibilidade, utilizamos --control-plane-endpoint juntamente com o IP do proxy.
Se todas as etapas forem concluídas com êxito, o resultado esperado é um output semelhante ao seguinte:
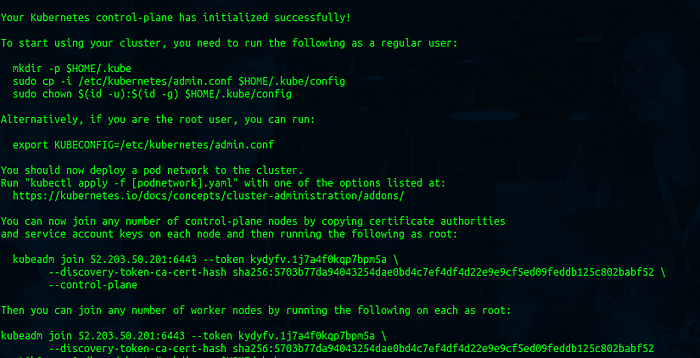
Vamos criar o kubeconfig para o kubectl interagir com o cluster
O kubeconfig é um arquivo de configuração utilizado pelo Kubernetes para especificar como interagir com um cluster Kubernetes. Este arquivo contém informações como o endereço do servidor do cluster, os detalhes de autenticação do usuário, e as configurações do contexto, que determinam o namespace padrão e outras opções de execução.
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/configInstalando o Container Network Interface (CNI)
Os clusters Kubernetes requerem a implementação de um Container Network Interface (CNI) para facilitar a comunicação entre os pods, tanto internamente quanto externamente. Dentre as opções disponíveis, optaremos pelo Calico Network Plugin neste cenário específico.
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.26.1/manifests/tigera-operator.yaml
curl https://raw.githubusercontent.com/projectcalico/calico/v3.26.1/manifests/custom-resources.yaml -O
sed -i 's/192.168.0.0\/16/10.40.0.0\/16/g' custom-resources.yaml
kubectl create -f custom-resources.yamlApós a conclusão da instalação do Calico CNI, observamos uma transição nos status dos pods do CoreDNS de “Pending” para “Running”, indicando que a comunicação está operacional.
Adicionando nós com join-command
É importante ressaltar que o comando de “join” é exibido após a conclusão da instalação do primeiro nós (control plane master).
kubeadm token create --print-join-commandEste é o output do comando:
kubeadm join <ELASTIC-IP>:6443 --token j4eice.33vgvgyf5cxw4u8i \
--discovery-token-ca-cert-hash sha256:37f94469b58bcc8f26a4aa44441fb17196a585b37288f85e22475b00c36f1c61Com o comando mencionado acima, você pode realizar o “join” de um nó de worker, no entanto, para incluir um nó de control plane, é necessário adicionar o certificado ao comando.
Gere o certificado:
kubeadm init phase upload-certs --upload-certsO output será semelhante a este:
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
86650ada3edec0f29141c008eb868bbd338d024e4af3c35427e82b3ed475fe72Agora que temos o certificado podemos fazer o join de uma control plane:
kubeadm join <ELASTIC-IP>:6443 --token epmmi0.o3ukd36kxg50e1nw \
--discovery-token-ca-cert-hash sha256:eae7f63e9903d118cba632a5a44c4740071b9a13d86edf8503ebadbaf63c546b \
--control-plane \
--certificate-key 86650ada3edec0f29141c008eb868bbd338d024e4af3c35427e82b3ed475fe72Observe que o parâmetro --control-plane é adicionado, junto com o parâmetro --certificate-key, seguido do valor gerado na etapa anterior.
Prossiga adicionando os nós restantes de controle e os nós de trabalho, seguindo as instruções acima e utilizando os comandos de “join” correspondentes.
Verifique os nós adicionados:
kubectl get nodes
O output é semelhante a este:
NAME STATUS ROLES AGE VERSION
k8s-cp-1 Ready control-plane 25d v1.28.1
k8s-cp-2 Ready control-plane 25d v1.28.1
k8s-cp-3 Ready control-plane 25d v1.28.1
k8s-worker-1 Ready <none> 25d v1.28.1
k8s-worker-2 Ready <none> 25d v1.28.1
k8s-worker-3 Ready <none> 25d v1.28.1Observe que os nós acima estão identificados na coluna “ROLES”. Isso é alcançado utilizando labels para organizar e identificar os nós de uma maneira mais estruturada.
Você pode adicionar labels com os seguintes comandos:
kubectl label node k8s-cp-1 node-role.kubernetes.io/control-plane=control-plane
kubectl label node k8s-worker-3 node-role.kubernetes.io/worker=worker
kubectl label node k8s-cp-3 node-role.kubernetes.io/etcd=etcdObserve a organização dos nós após a atribuição das labels:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-cp-1 Ready control-plane,etcd 25d v1.28.1
k8s-cp-2 Ready control-plane,etcd 25d v1.28.1
k8s-cp-3 Ready control-plane,etcd 25d v1.28.1
k8s-worker-1 Ready worker 25d v1.28.1
k8s-worker-2 Ready worker 25d v1.28.1
k8s-worker-3 Ready worker 25d v1.28.1Veja que as labels “worker” e “etcd” foram atribuídas e estão sendo exibidas, proporcionando uma identificação mais clara e organizada dos nós no cluster.
Realizando manutenção dos nós
Em situações específicas, pode ser necessário remover um nó de control plane ou um nó de worker. Para isso, é preciso executar um “drain”.
O “drain” refere-se a um procedimento que marca um nó como indisponível para receber novas cargas de trabalho, preparando-o para manutenção, atualizações ou, eventualmente, para ser removido do cluster. O comando kubectl drain é utilizado para esse fim.
kubectl drain <NODE-NAME>Observação: O parâmetro --ignore-preflight-errors pode ser necessário caso existam daemonsets ativos. Isso garantirá que o nó, seja ele um control plane ou um worker, seja esvaziado corretamente.
Após o “drain” do nó, ele ficará com o status “NoSchedule”, proporcionando as opções de remoção completa, execução de um reset ou uma manutenção específica se for caso.
Removendo o nó:
kubectl delete node <NODE-NAME>Realizando um reset:
kubeadm resetPara adicionar um novo nó ao cluster, basta seguir as etapas desde o início deste procedimento, adaptando-as ao tipo de nó, seja control plane ou worker. A inclusão do nó segue o mesmo processo, independentemente de ser uma nova instalação (em uma nova instância) ou após um kubeadm reset.
Arquivos de configuração
- Localização de pods estáticos (etcd, api-server, gerenciador de controlador e agendador) /etc/kubernetes/manifests
- Localização dos certificados TLS (kubernetes-ca, etcd-ca e kubernetes-front-proxy-ca) /etc/kubernetes/pki
- Arquivo Admin Kubeconfig /etc/kubernetes/admin.conf
- Configuração do Kubelet /var/lib/kubelet/config.yaml
Espero ter contribuído com estas instruções. Como entusiasta do ecossistema Kubernetes, ajudar no crescimento de outras pessoas é uma forma de expressar minha gratidão por ter aprendido com alguém no passado.
Este ambiente proporciona uma configuração ideal para estudos visando os exames da Certified Kubernetes Administrator (CKA). Aproveite este artigo como oportunidade para aprofundar seus conhecimentos e boa sorte em seus estudos!
Veja tambem este artigo no LinkedIn: https://www.linkedin.com/pulse/criando-um-cluster-kubernetes-em-alta-disponibilidade-erivaldo-lopes-3jtmf